Sometimes I assume that everybody I work with come from the same background of mine; front end web designing with coding expertise all mixed up with roughly 10 years of digital marketing expertise.
Clearly I’m wrong; and making the wrong assumptions can cost quite a lot time when it comes to verify how the job you delegated is done.
Today I’d like to point you out on something that probably as a SEO you use quite often: the Inspect Element of your browser.
According to the browser you are using, the code-name of the product is changing: for example, Firefox comes with Firebug, Safari with WebKit’s web inspector, Opera with Dragonfly, Chrome with (ehmm) Chrome Developer Tools. Regardless the name, the Inspect Element will let you see the DOM of your page as the browser sees it.
That’s where this tool can actually cause you problems, or at least a bit of confusion.
When you choose “Inspect element” or otherwise bring up one your browser’s DOM inspector, what you’re looking at is the document tree after the browser has applied its error correction and after any JavaScripts have manipulated the DOM (all is depending on the specific quirks and feature support). So, in few words the Inspect elements doesn’t necessarily show the same as you see when you choose “View source”, which is exactly what the server returns.
Apparently there is anything that SEOers or Web developers can do to get the full source code if not using the “view source” panel of your browser.
Of course this is not the only “problem” you may face with. For example, the View Source in Chrome sends another request for retrieving again the URL; in the majority of the circumstances this is ok, but there could be a case where a web site requires the authentication and since Chrome request it’s not authenticated you may be returned the source of the login page.
Different story for Internet Explorer, where the source code shown is the one of the page cached a few moments before.
I may keep going with differences for another chapter or two at very least, but this is not the reason I wrote this post, although it is a shame there is not a “switch mode” that enable quick to show the portion of “unrendered” code in a simple snap.
This is all nice, but…
Why should I know how my tools work?
Well, I would expect a professional being able to use his own toolkit, regardless the industry is working in because in this way tasks can be completed quicker and more efficiently. Simple as that.
This is clearly not a complain towards those juniors that are learning the foundation of the job, but more a warning for those professionals that treat – in the SEO case - the findings of their job very superficially without digging around when ideally this is required.
Cool … but why are telling me this? I’m a pro after all.
I wasn’t doubting this in any way; however, a couple of days ago, I’ve been involved in a conversation where apparently we were in front of one of those case of “link selling” which Penguin should have been able to detect straight away but it didn’t.
According to the claimer, the link was passing the juice, and this was totally unfair and not respecting the guidelines.
I have had a look at both sites, then I answered back to the author of the thread by saying that IMHO there were anything wrong, and that although border-line the case is ok. I let you imagine the reactions (and the insults) I received over the followings minutes by all participants.
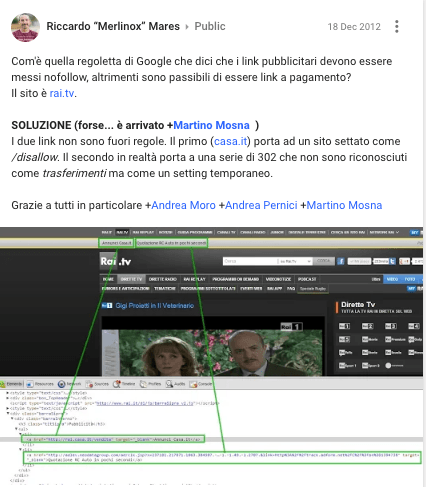
To let you understand, that’s the scenario: the web site is the one of National Italian Television Rai.it accused to sell links by placing two links underneath the main navigational bar as shown in the picture below.
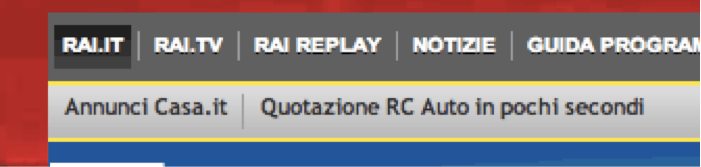 As a matter of fact, Rai declares those links to be promotional Ads - as stated on the right hand side of the bar - so in theory there is anything wrong with this. }And in fact the nature of the conversation suddenly moved to the SEO technical implementation and the infringements of the SEO guidelines.
As a matter of fact, Rai declares those links to be promotional Ads - as stated on the right hand side of the bar - so in theory there is anything wrong with this. }And in fact the nature of the conversation suddenly moved to the SEO technical implementation and the infringements of the SEO guidelines.
What Google says in regards of the paid links?
We all know what the webmasters’ guidelines say in regards of the promotional link, don’t we? As a refresher, Google says it is prohibited buying or selling links that pass PageRank. This includes:
- exchanging money for links,
- posts that contain links
- exchanging goods or services for links
- sending someone a “free” product in exchange for them writing a review
- including a link where it is not allowed (or clearly inappropriate)
In the same page, Google also provides for people involved in “content marketing” activities by saying a link can be passed in this way provided it doesn’t pass PageRank that you can stop with several method such as:
- Adding a rel=“nofollow” attribute to the
<a>tag - Redirecting the links to an intermediate page that is blocked from search engines with a robots.txt file
Now the scenario is a bit clearer, let’s analyze all together the diatribe.
The first claim: this is a direct link
That’s the main reason I wrote this article. I’m quite confident an inaccurate initial check has been done without considering both the links are part of a Display network, hence they are generated via JavaScript (no direct link at all). However, having a look at the code with the Inspect Element, at first sights they appear to be as such.
On top of this, although Google’s capacity to analyse Javascript code, during my previous tests, I have never been able to demonstrate myself juice to be passed via these links.
The second claim: there isn’t the nofollow attribute
Ok, this is true. And apparently links are not respecting the guidelines.
Again, links are the result of JavaScript code and in theory there is not a real necessity to append the nofollow attribute, though the inclusion would probably make Rai.it more respectful of the guidelines.
On their defense, it must be said Rai has very little (if no control at all) of the code output, and the Display provider is the only company responsible of this.
The third claim: perhaps the disallow in the robots.txt will make the targeted site in line with the webmaster guideline.
After I came back by saying that I wasn’t able to devise responsibilities, inviting people to have a better look at the site, the persons involved in the conversation finally start digging around a bit more, and the targeted site entirely disallowed via the robots.txt has been mentioned.
Now, here another big problem: people don’t read, or at least do this superficially!
Google Webmasters’ guidelines mention the nofollow or the intermediate robots.txt file as an indication making a site compliant, but again this not an exhaustive list.
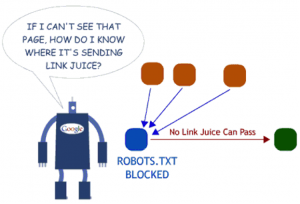
In this particular case, although it is the targeted site to contain the robots.txt with the disallow directive, if you think to this scenario holistically, suddenly you will understand there should be not any capacity for the link to pass PageRank.
Persons took part to the discussion were saying the opposite, however none of them bring in any real example to confirm their statement (so didn’t I), but I bet the above image (found on SeoMoz) explains the concept very well.
The fourth claim: all URLs contain a canonical tag as well as a 301 redirect
Although this is true, I believe the destination web site casa.it implemented both the canonical and the redirect prior activating the advertising.
Again robots.txt prevents Google to access the site and the file already indexed are in theory useless for the sake of their back link profile rather more a precaution to avoid problems due to the canonicalization.
In conclusion…
Webmaster’s guidelines provided by Google offer a clear vision of what paid links are and some straight forward (though not complete) suggestions for the implementations. In my opinion, something that should be made clear is how links between “properties” or “partnered” web site should be created.
In fact, by doing a research on Internet, it appears that rai.it and casa.it partnered the two site back in 2009.
From an investigation point of view instead, I would like people involved in the conversation to be more cautious before pointing fingers, and try to understand sites are not all the same and search engines algorithm attempts to solve problems scaling down problems as a whole and not individually.
As usual, the articles represents my point of view. I am not associated with Google or Rai, and this has been written purely to technically dissect and brings in to the table the answer to the “questions” emerged during the G+ conversation.